
Back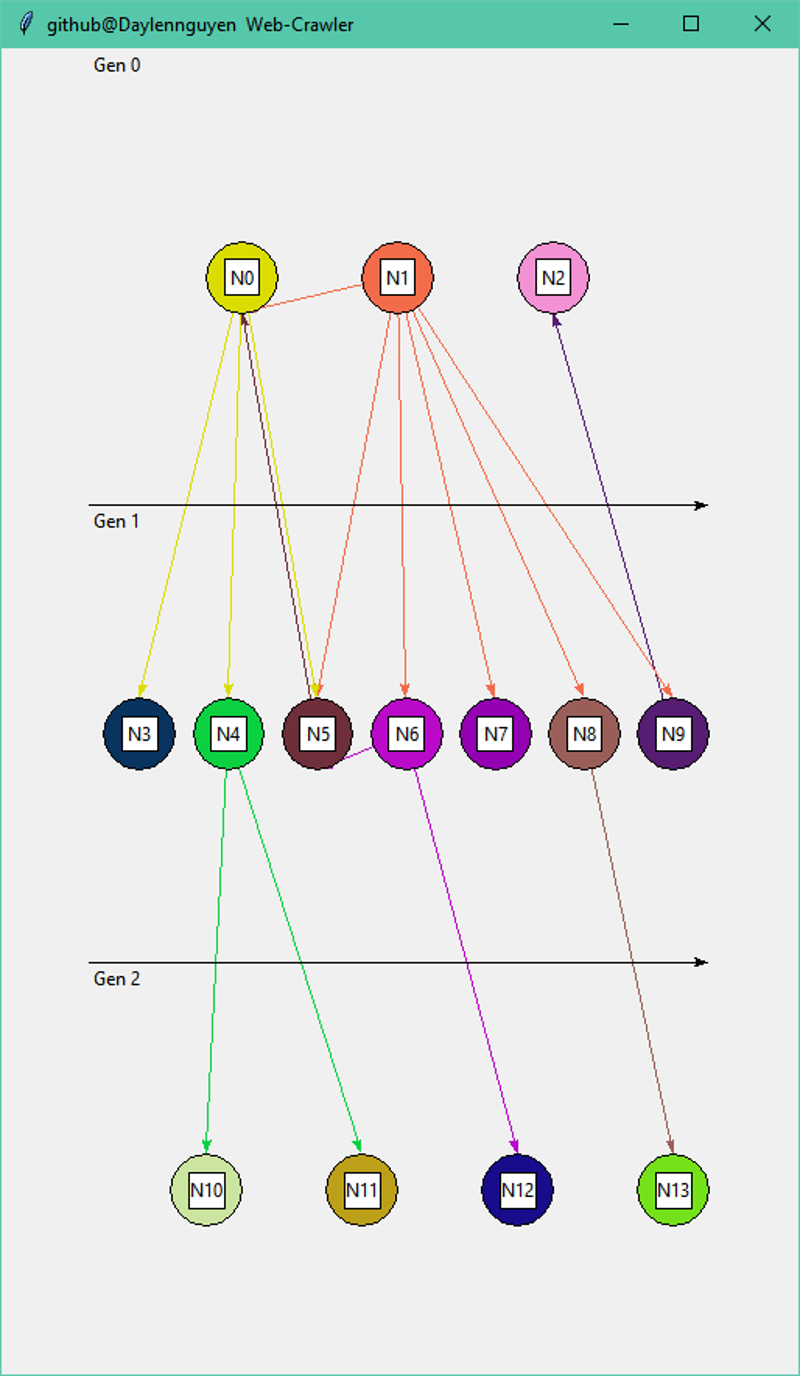
Python Web Crawler w/ Regex
Python script which accepts a urls text file (urls.txt) in the root directory, of which contains a line seperated list of URLS to webcrawl/scan. More specifically, scans each HTML page served at the URL then parses the results for links to which will output a CSV file containing the results.
Python script which accepts a urls text file (urls.txt) in the root directory, of which contains a line seperated list of URLS to webcrawl/scan. More specifically, scans each HTML page served at the URL then parses the results for links to which will output a CSV file containing the results.